개발 공부
[운영체제][OSTEP] 지역성과 Fast File System
성능 개선을 위해 디스크 특성을 파일 시스템에 반영한 FFS에 대해 공부해봅니다.





![[운영체제][OSTEP] 지역성과 Fast File System](https://www.datocms-assets.com/66479/1686988115-ostep.jpg?auto=format&w=860)
🚪 들어가며
Unix의 창시자 Ken Thompson이 개발한 첫 번째 파일 시스템은 정말 단순해서 "오래된 Unix 파일 시스템"이라 불림.
디스크 상의 구조는 다음과 같음.
┌───┬────────┬──────────────────────────────┐
│ S │ Inodes │ Data │
└───┴────────┴──────────────────────────────┘슈퍼블럭(S): 볼륨 크기, 아이노드 개수, 프리 블럭 리스트의 헤드를 가리키는 포인터 등이 존재
아이노드 영역: 모든 아이노드들이 존재
데이터 영역
✅ 장점은 단순하다는 것
➡️ 파일 시스템의 가장 기본적인 개념인 파일과 디렉터리만을 제공
1️⃣ 문제: 낮은 성능
⚠️ 문제는 성능이 매우 안좋다는 것
➡️ 디스크를 마치 RAM처럼 사용함.
➡️ 여기저기에 데이터를 저장하여 디스크 헤드를 이동시키는 데 많은 시간이 소요됨.
예를 들어 아이노드를 읽은 후 해당 데이터 블럭을 읽는 매우 흔한 작업의 경우
➡️ 파일의 데이터 블럭이 대체적으로 아이노드에서 멀리 떨어져 있기 때문에 디스크 헤드 이동에 많은 시간을 소요하게 됨.
⚠️ 심지어 파일 시스템이 빈 공간을 효율적으로 관리하지 않기 때문에 결국 단편화(fragment) 문제도 발생
➡️ 🚫 성능이 심각하게 나빠짐.
각 2개의 블럭의 크기를 갖는 네 개의 파일(A, B, C, D) 중 B와 D를 삭제한 후 4개의 블럭으로 구성된 파일 E를 할당하는 경우를 가정해보자.
[1] 파일 A, B, C, D 존재
┌────┬────┬────┬────┬────┬────┬────┬────┐
│ A1 │ A2 │ B1 │ B2 │ C1 │ C2 │ D1 │ D2 │
└────┴────┴────┴────┴────┴────┴────┴────┘
[2] 파일 B, D 삭제
┌────┬────┬────┬────┬────┬────┬────┬────┐
│ A1 │ A2 │ │ │ C1 │ C2 │ │ │
└────┴────┴────┴────┴────┴────┴────┴────┘
[3] 파일 E 할당
┌────┬────┬────┬────┬────┬────┬────┬────┐
│ A1 │ A2 │ E1 │ E2 │ C1 │ C2 │ E3 │ E4 │
└────┴────┴────┴────┴────┴────┴────┴────┘이와 같이 E를 이루는 블럭들이 디스크 상에서 흩어져 있게 됨.
➡️ E를 읽거나 쓸 경우, 디스크로부터 최대(순차) 성능을 얻을 수 없음.
➡️ ✅ 조각 모음 도구를 통해 이 문제를 해결해볼 수 있음.
⚠️ 또 다른 문제는 블럭의 크기(512 바이트)가 너무 작다는 것
➡️ 입출력 단위가 너무 작기 때문에 디스크로부터 데이터를 전송하는 것은 원천적으로 매우 비효율적
✅ 작은 크기의 블럭은 내부 단편화(internal fragmentation)가 작은 장점이 있음.
⚠️ 그러나, 디스크 헤드의 이동시간에 비해 데이터 블럭의 크기가 작아 입출력이 상대적으로 비효율적
2️⃣ FFS: 디스크에 대한 이해가 해답이다
Berkeley의 한 그룹이 더 낫고 빠른 파일 시스템을 만들기로 결정하고 Fast File System, FFS라고 명명함.
💡 파일 시스템의 자료 구조와 할당 정책을 "디스크에 적합"하게 설계하여 성능을 개선하는 것이 핵심
✅ 파일 시스템 인터페이스(open(), read(), write(), close() 등의 파일 시스템 콜)는 그대로 유지하면서 내부 구현 방식을 변경함.
3️⃣ 파일 시스템 구조: 실린더 그룹
첫 번째 단계는 디스크에 적합하게 파일 시스템 구성을 수정하는 것이었음.
💡 FFS는 디스크를 여러 개의 실린더 그룹(cylinder group, 현대 Linux의 ext2, ext3에서는 블럭 그룹(block group)으로 부르기도 함)으로 분할함.

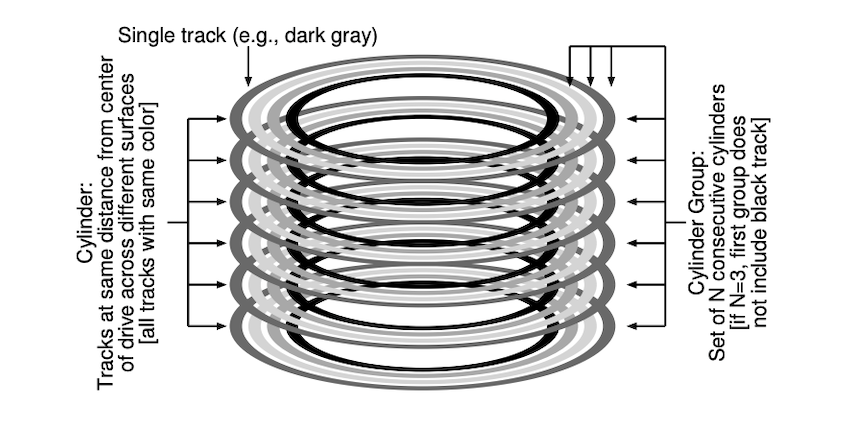
하나의 실린더는 위의 그림에서 같은 색의 원들이 모여서 구성
➡️ 드라이브 중심에서 같은 거리만큼 떨어진 각 표면의 트랙들의 집합
FFS는 N개의 연속된 실린더를 모아서 하나의 그룹으로 만듦.
➡️ 전체 디스크가 실린더 그룹의 모임으로 보여질 수 있음.
➡️ 위의 그림에서 3개의 실린더가 모여서 하나의 실린더 그룹을 형성함.(N = 3)
💡 메모리 가상화에서 그랬듯, 최신 드라이브는 특정 실린더가 사용 중인지 파일 시스템이 제대로 파악할 만큼 충분한 정보를 내보내지 않고 블록으로 구성된 논리 주소 공간을 내보내고 클라이언트로부터 형상의 세부 정보를 숨김.
➡️ 따라서 현대식 파일 시스템(예: Linux ext2, ext3, ext4)은 대신 드라이브를 블록 그룹으로 구성하고 각 블록은 디스크 주소 공간의 연속적인 배열에 불과함.
실린더 그룹이 열 개 있는 디스크를 다음과 같이 생각해볼 수 있음.
┌────┬────┬────┬────┬────┬────┬────┬────┬────┬────┐
│ G0 │ G1 │ G2 │ G3 │ G4 │ G5 │ G6 │ G7 │ G8 │ G9 │
└────┴────┴────┴────┴────┴────┴────┴────┴────┴────┘🛸 실린더 그룹은 FFS의 핵심 중의 핵심
➡️ 두 개의 파일을 같은 그룹에 배치시켜서 한 파일을 읽고 다음 파일을 접근할 때 디스크 전역에 걸친 긴 탐색이 발생하지 않도록 함.
💡 FFS는 파일과 그 파일이 속한 디렉터리 블럭을 같은 그룹에 할당함.
➡️ 그룹이 꽉 차면 밀려나는 경우가 발생할 수 있음.
각 그룹은 다음과 같이 구성됨.
┌───┬────┬────┬────────┬──────────────────────────────┐
│ S │ ib │ db │ Inodes │ Data │
└───┴────┴────┴────────┴──────────────────────────────┘슈퍼블럭의 복사본(S)이 각 그룹마다 존재
➡️ 하나가 훼손되더라도 다른 것을 사용하여 파일 시스템을 마운트하고 접근할 수 있음.
그룹 별로 아이노드 비트맵(ib)과 데이터 비트맵(db)이 존재
➡️ 각 그룹의 아이노드와 데이터 블럭의 할당 정보를 나타냄.
➡️ 비트맵은 파일 시스템의 빈 영역을 나타내는 훌륭한 방법임.
➡️ 큰 크기의 연속된 빈 공간을 쉽게 찾을 수 있음.
➡️ 프리 시스트 사용 시 발생하는 파일 시스템의 단편화 문제도 어느 정도 피할 수 있음.
아이노드와 데이터 블럭 영역은 위의 아주 단순한 파일 시스템에서 봤던 것과 동일
➡️ 각 실린더 그룹의 대부분도 마찬가지로 데이터 블럭들로 이루어져 있음.
4️⃣ 파일과 디렉터리 할당 정책
성능 개선을 위해 파일과 디렉터리 및 관련된 메타데이터를 디스크에 어떻게 배치해야할지를 결정해야 함.
➡️ 💡 기본 원칙은 "관련있는 것끼리 모으는" 것
이를 위해서는 우선 무엇이 "관련있는" 지 파악하여 그것들을 같은 블럭 그룹 내에 저장함.
➡️ 반대로 관련없는 항목들은 서로 다른 블럭 그룹에 저장
💡 이를 달성하기 위해 FFS는 몇 가지 힌트를 사용함.
첫 번째는 디렉터리의 위치 결정에 관한 것
할당된 디렉터리의 수가 적고(그룹들 간에 디렉터리에 대한 균형을 맞추기 위해) 프리 아이노드의 수가 많은 실린더 그룹을 선택하여 디렉터리 데이터와 아이노드를 해당 그룹에 저장
➡️ 프리 데이터 블럭의 수를 고려하는 등 다른 방법을 따를 수도 있음.
파일의 경우 FFS는 두 가지 방법을 사용함.
(일반적인 경우에) 아이노드와 파일의 데이터 블럭을 같은 그룹에 할당하여 아이노드와 데이터 간의 긴 탐색을 방지
➡️ 오래된 파일 시스템과 같은 방식
동일한 디렉터리 내의 모든 파일들은 해당 디렉터리가 존재하는 실린더 그룹에 함께 저장
⚠️ 이러한 방식은 상식(common sense)에 기반한 것
➡️ 파일 시스템 사용에 관한 완벽한 분석이나 그와 유사한 무엇을 통해 나온 것이 아님.
디렉터리 내의 파일들은 대체적으로 같이 접근이 됨.
➡️ ✅ 관련 파일들 간의 탐색이 짧아지기 때문에 FFS는 성능을 개선할 수 있음.
5️⃣ 파일 접근의 지역성 측정
이러한 경험적 상식에 근거한 접근이 정당한지를 알기 위해 namespace 지역성이 실제 존재하는지 알아보자.
SEER 트레이스를 사용하여 디렉터리 트리 내에서 파일 간의 접근이 얼마나 "멀리 떨어져" 있는 지를 분석함.
➡️ 거리 기준 = 두 파일의 조상 경로명이 동일하게 될 때까지 디렉터리 트리를 얼마나 타고 올라가야 하는지
예를 들어 다음과 같음.
파일 open 간의 거리 0
파일
f가 열린 후 다른 파일이 열리기 전에 다시 그 파일이 열린 경우
파일 open 간의 거리 1
파일
/dir/f가 열린 후 다른 파일이 열리기 전에 파일/dir/g가 열린 경우
즉, 트리 상에서 가까이 있을수록 낮은 값을 갖게 됨.
다음은 SEER 클러스터에 속해 있는 여러 워크스테이션들의 전체 트레이스를 합하여 지역성을 나타낸 것
➡️ 경로 간의 거리를 x축에, 이에 대한 누적 빈도를 y축에 표현

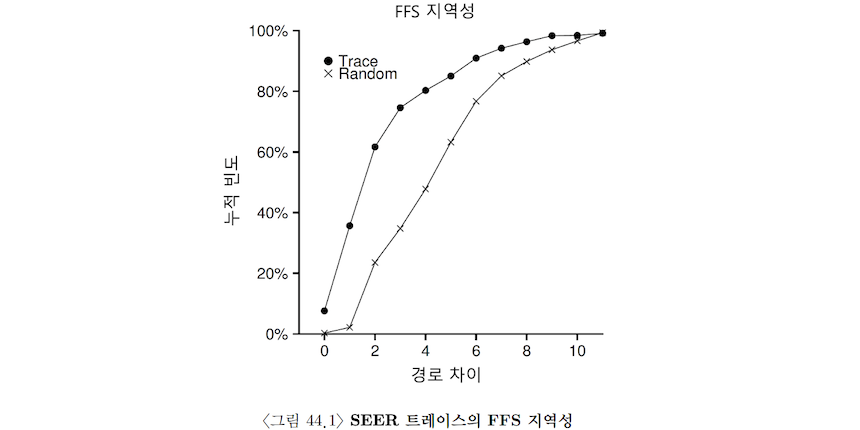
"Trace"는 일반적인 경우, "Random"은 비교를 위한 파일 임의 접근 트레이스임.
먼저 Trace의 결과를 살펴보자.
약 7%가 직전에 열었던 파일을 다시 열었음.
거의 40%의 경우가 같은 디렉터리 내의 파일 또는 같은 파일을 열었음.
25% 정도는 경로가 2만큼 떨어져 있음.
➡️ 이 현상은 사용자가 서로 관련된 디렉터리들을 묶어두고 이들 디렉터리에 존재하는 파일들을 번갈아 접근할 때 발생하는 것으로 판명됨.
Random 트레이스의 경우 이름 공간의 지역성이 낮은 것을 볼 수 있음.
➡️ 하지만 결국 모든 파일은 루트와 같은 동일한 조상을 갖기 때문에 약간의 지역성은 보임.
6️⃣ 대용량 파일 예외 상황
파일 배치 시 예외 상황이 있음.
➡️ 파일 크기가 매우 큰 경우
⚠️ 별도의 규칙을 적용하지 않으면 하나의 파일이 블럭 그룹(과 다른 블럭들)을 모두 채울 수 있음.
➡️ 이는 그 뒤의 "관련"있는 파일들을 다른 블럭 그룹에 저장되도록 만들어 파일 접근 지역성을 떨어뜨리게 됨.
FFS는 큰 파일들의 배치를 다음과 같이 처리함.
첫 번째 블럭 그룹에 일정 수의 블럭을 할당
파일의 "큰" 청크를 다른 블럭 그룹(사용률이 낮은 것으로 선택)에 저장
파일의 다음 청크는 마찬가지로 또 다른 블럭 그룹에 저장
다음 예시를 통해 이를 조금 더 이해해보자.
만약 큰 파일에 대한 예외 처리 없이 저장한다면 다음과 같이 될 것임.
G0 G1 G2 G3 G4 G5 G6 G7 G8 G9
┌─────┴─────┐
│ 0 1 2 3 4 │
│ 5 6 7 8 9 │
└───────────┘큰 파일에 대한 예외 처리를 한다면 다음과 같이 파일은 디스크 전반에 걸쳐 청크 단위로 저장될 것임.
G0 G1 G2 G3 G4 G5 G6 G7 G8 G9
┌┴──┐ ┌─┴─┐ ┌─┴─┐ ┌─┴─┐ ┌─┴─┐
│8 9│ │0 1│ │2 3│ │4 5│ │6 7│
└───┘ └───┘ └───┘ └───┘ └───┘⚠️ 다만 이렇게 하면 상대적으로 흔한 순차 파일 접근과 같은 경우에 성능이 좋지 않게 됨.
➡️ ✅ 청크의 크기를 적절히 선택하는 것으로 이 문제를 약간 경감시킬 수 있음.
만약 청크의 크기가 충분히 크다면, 디스크로부터 데이터를 전송하는 데 대부분의 시간을 사용하고 상대적으로 적은 시간을 블럭 청크들 간의 탐색에 사용하게 될 것임.
➡️ 오버헤드 비용당 더 많은 작업을 처리하여 오버헤드를 줄이는 것을 점진적 경감(amortization) 기법이라고 부름.
예를 들어 다음과 같은 상황을 가정하여 목적 달성을 위한 청크 크기를 계산해보자.
디스크 평균 위치 잡기 시간(탐색과 회전 시간)이 10 ms
디스크가 데이터를 40 MB/s의 속도로 전송
전체 시간 중 탐색에 반을 사용하고 나머지를 데이터 전송에 쓰는 것이 목적
➡️ 최대 디스크 성능의 50%
40 MB 1024 KB 1 sec
───── * ─────── * ─────── * 10 ms = 409.6 KB
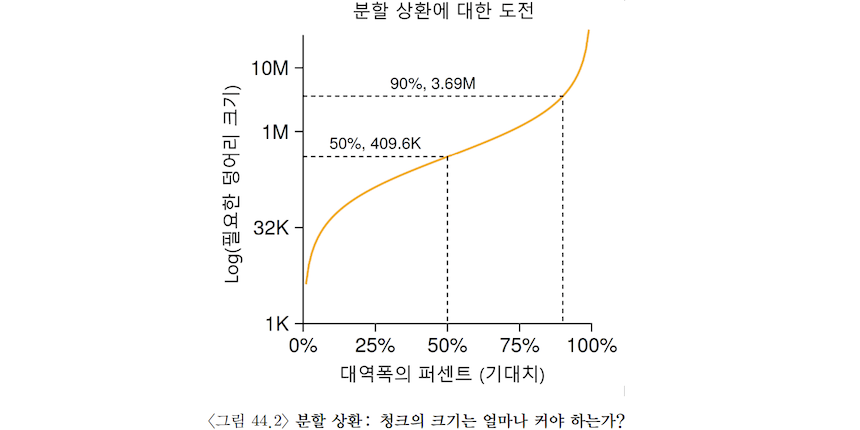
sec 1 MB 1000 ms즉, 이 경우 매 탐색마다 409.6KB의 데이터를 전송해야 한다는 것을 의미
동일한 환경에서 최대 대역폭의 90%를 달성하기 위한 청크의 크기 = 3.69 MB
동일한 환경에서 최대 대역폭의 99%를 달성하기 위한 청크의 크기 = 40.6 MB
✅ 최대 대역폭에 가까운 성능을 원할수록 청크의 크기가 커지는 것을 볼 수 있음.
이를 그래프로 나타내면 다음과 같음.

🛸 한편, FFS는 큰 파일을 그룹들 간에 분산하는 데 있어 이와 같은 계산을 사용하지 않았음.
➡️ 대신 아이노드 자체의 구조를 기반으로 하는 간단한 접근법을 사용함.
💡 첫 번째 열두 개의 직접 블럭은 아이노드와 같은 그룹에 배치하였고, 각 간접 블럭과 그것이 가리키는 모든 블럭들은 다른 그룹에 배치함.
블럭 크기가 4KB이고 32비트 디스크 주소를 사용한다고 할 때 이 전략은 직접 포인터가 가리키는 파일의 첫 48KB만 예외로 할당되고 파일의 매 1024개의 블럭(4KB)마다 다른 그룹에 배치됨.
7️⃣ FFS에 대한 기타 사항
✅ FFS는 혁신적인 기법을 개발하여 적용했고, 특히 작은 파일들을 효율적으로 저장하기 위해 많은 노력을 함.
당시 2KB 크기의 파일들이 많았는데, 4KB 블럭을 사용함에 따라 데이터 전송에 이득이 있었던 반면 공간 활용면에서는 비효율적이었음.
➡️ 일반 파일 시스템에서는 내부 단편화(internal fragmentation)로 인해 대략 반 정도의 공간이 낭비됨.
✅ FFS 설계자들은 이 문제를 해결하기 위해 파일 시스템이 파일을 할당할 수 있도록 512 byte의 서브블럭(sub-block) 개념을 도입함.
작은 파일(1KB 크기)을 생성할 때, 두 개의 서브블럭을 할당함으로써 4KB 블럭 전체가 낭비되는 경우가 발생하지 않도록 함.
파일이 커지면 파일 시스템은 4KB가 될 때까지 512 byte 크기의 블럭들을 추가로 할당함.
➡️ 서브블럭들의 합이 4KB가 되는 시점에 FFS는 4KB 블럭을 찾아서 서브블럭들을 복사해 넣은 후에 해당 서브블럭들을 다시 사용할 수 있도록 해제함.
파일 시스템의 추가 동작이 많이 발생함에 따라 과정이 비효율적이 될 수 있음.
➡️ 💡 FFS는 이러한 경우를 피하기 위해 libc 라이브러리를 수정함.
라이브러리는 쓰기 요청을 버퍼에 두었다가 4KB 청크가 되면 파일 시스템에 내리는 식으로 대부분의 서브블럭을 사용하는 특수한 경우를 완전히 제거할 수 있도록 함.
FFS에서 개발 채택된 또 하나의 기발한 아이디어가 있음.
➡️ 성능에 최적화된 디스크 배치
FFS의 문제는 디스크에 연속적인 섹터들에 파일을 저장해야 할 때 발생했음.
➡️ 디스크 트랙을 따라 연속적으로 나열된 블럭을 순차적으로 읽는 경우
예를 들어 FFS가 먼저 블럭 0번에 대한 읽기를 요청하고 그 요청이 끝난 뒤 블럭 1번에 대한 읽기를 요청하는 경우
➡️ ⚠️ 이미 헤드가 블럭 1을 지나감. = 1번 블럭을 읽기 위해 한 바퀴를 다 돌아야 함.
✅ FFS는 이 문제를 디스크의 배치를 바꾸는 식으로 해결함.
➡️ 즉, 예시의 경우 블럭 0과 블럭 1이 연속되지 않게 배치하여 블럭이 헤드 아래로 지나가기 전에 해당 블럭을 요청할 충분한 시간을 벌 수 있었음.
🛸 사실 FFS는 추가 회전을 피하기 위해서 특정 디스크의 몇 개의 블럭을 건너뛰어서 배치할지 알 만큼 영리하였음.
➡️ FFS는 디스크의 특정 성능 매개변수들을 검출해 낸 후에 그 정보를 활용하여 정확한 시차에 따라 배치 기법을 결정할 수 있도록 함.
➡️ FFS는 이 기법을 매개화(parameterization)라 부름.
이러한 배치 기법을 사용하면 최대 대역폭의 50% 밖에 얻을 수가 없음.
➡️ 트랙의 모든 블럭을 한 번씩 읽기 위해서 같은 트랙을 두 바퀴 돌기 때문
➡️ ✅ 현대의 디스크들은 내부적으로 한 트랙을 모두 내부 디스크 캐시(트랙 버퍼)에 버퍼링하여 해당 트랙에 연달아 읽기 요청이 들어오면 디스크는 캐시에서 원하는 값을 리턴함.
파일 시스템은 그러므로 더 이상 하위 수준의 상세한 부분에 대해서는 신경쓰지 않아도 됨.
사용자 편의성을 개선하기 위한 기능들도 추가됨.
FFS는 긴 파일 이름을 지원하는 최초의 파일 시스템 중 하나임.
FFS는 심볼릭 링크 개념을 도입한 최초의 파일 시스템임.
FFS는 파일의 이름을 원자적으로 변경하는
rename()명령도 소개함.
기본적인 기술 이외에도 사용성을 개선한 기법들로 인해서 FFS는 두터운 사용자 층을 얻을 수 있었음.
📚 참고 문헌
Operating Systems: Three Easy Pieces ― 41: Locality and The Fast File System

![[운영체제][OSTEP] 파일 시스템 구현](https://www.datocms-assets.com/66479/1686988115-ostep.jpg?ar=1&auto=format&crop=focalpoint&dpr=0.47&fit=crop&fp-x=0.5&fp-y=0.5&w=430)